LRU算法
LRU(Last Recently Used)算法一般用在缓存,作为一种缓存淘汰的机制,即淘汰掉最近最少使用的记录。其要求一般为:
- 维护一个固定大小的缓存。
- 当缓存满时,若要增加新元素,需先淘汰掉缓存中最久未使用的元素。
- 元素最近一次访问的时间离当前越近,越不容易被淘汰。
¶LeetCode题目:

¶解题思路
-
题目要求put()、get()操作的时间复杂度为O(1),最合适的数据结构应当为HashMap。
-
此外,当容量满时,我们要淘汰掉最近最少使用的元素。
我们可能会想到队列,它是一个先进先出的数据结构,用队列能很快捷地淘汰掉最老的元素,但却不能淘汰掉最近最少使用的元素!
所以我们需要一种机制判断每个元素最近使用的频繁程度,给元素加上一个计数器么?naive!这样要花线性时间遍历才能找到最近最少使用的元素!
其实队列已经很接近最终结果了,我们要做的只是一点点改进——每次get()获取到缓存中的值后,还要把它从队列里挖出来,再让它到队尾去重新排队,缓存满了我们就淘汰掉队头那些最近都没用到的元素。这样就很好地解决了“最近最少使用”这个问题。
-
所以最终的解决方案为:
HashMap<key,队列节点> + 基于双向链表的队列
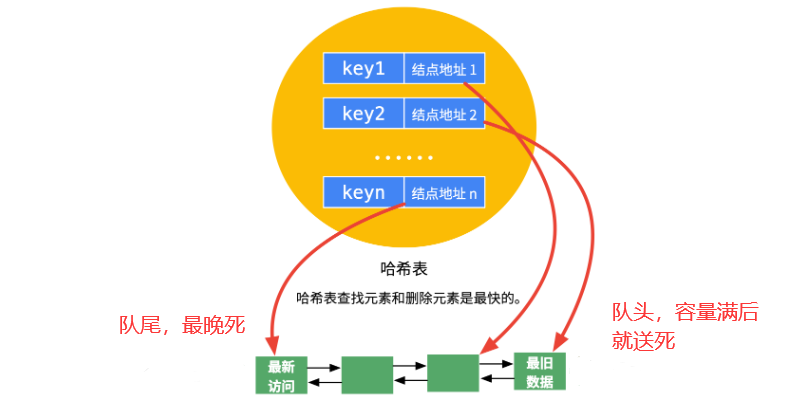
-
一个比喻:
排队的时候,队列中某人被叫去处理点事,等回来后他就得重新排队,就是这个规矩。
¶代码:
要求:15min之内手写完!作为高频题目,必须多练习
/**
*
* 执行用时 : 18 ms , 在所有 Java 提交中击败了 97.28% 的用户
* 内存消耗 : 47.9 MB , 在所有 Java 提交中击败了 100.00% 的用户
*/
class LRUCache {
int capacity;
int currentSize=0;
HashMap<Integer,Node> map;
Node head;
Node tail;
public LRUCache(int capacity) {
map=new HashMap<>(capacity);
this.capacity=capacity;
}
/**
* 考虑情况:
* 1. 该节点为tail,直接返回其值
* 2. 该节点不为tail,且存在于缓存中,挪到tail后面成为新tail,返回其值
* 3. 该节点不存在于缓存,返回-1
*/
public int get(int key) {
Node node=map.get(key);
if(node!=null){
if(node!=tail){
moveToTail(node);
}
return node.val;
}else{
return -1;
}
}
/**
* 考虑情况:
* 1. 缓存中存在该key,直接更新对应节点的value
* 2. 缓存中不存在该key:
* 若缓存已满,先从map和双向链表中淘汰掉head节点,即最近最少使用节点
* 生成新节点node:
* 缓存为空(刚刚初始化),tail,head指向node;
* 缓存不为空,新节点node加入map,在链表中放到到tail后,成为新的tail
*/
public void put(int key, int value) {
Node exist=map.get(key);
if(exist==null){ //缓存中不存在该 kv 对
if(currentSize>=capacity){ //缓存满了,挤走head
Node new_head=head.next;
if(new_head!=null){
new_head.prev=null;
}
head.next=null;
map.remove(head.key);
head=new_head;
currentSize--;
}
Node node=new Node(key,value);
if(tail==null){ //缓存为空
head=node;
tail=node;
}else{ //缓存不空
tail.next=node;
node.prev=tail;
tail=node;
}
map.put(key,node);
currentSize++;
}else{
exist.val=value;
moveToTail(exist);
}
}
/**
* 挪到tail位置成为新tail
* 情况分析:
* 1. node就是tail,不做任何操作,直接返回
* 2. node不是tail,让其前后节点互相指向,将其挪到tail后面,成为新的tail:
* 如果node为head,head指向node_next
* tail指向node
* @param node 待交换节点
*/
private void moveToTail(Node node){
if (node==tail)return;
Node node_prev=node.prev;
Node node_next=node.next;
if(node_prev!=null){
node_prev.next=node_next;
}
if(node_next!=null){
node_next.prev=node_prev;
}
node.prev=tail;
tail.next=node;
node.next=null;
if (head==node)head=node_next;
tail=node;
}
class Node{
int key;
int val;
Node prev;
Node next;
Node(int key,int val){
this.key=key;
this.val=val;
}
}
}
¶扩展点:
-
哨兵写法(dummy head、dummy tail)
-
如何保障线程安全?
-
加锁:synchronize method
-
如何保障高效(high throughput):CAS操作
-
ConcurrentHashMap(分段锁)
-
容忍一定的读写精确性损失(读写锁)
-
-
能不能做成环形而不是双向链表?
-
提前分配空间(HashMap)
-
分布式环境下LRU怎么解决?
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达,邮件至 708801794@qq.com
文章标题:LRU算法
文章字数:1k
本文作者:梅罢葛
发布时间:2020-04-08, 22:14:01
最后更新:2020-04-08, 23:58:18
原始链接:https://qiurungeng.github.io/2020/04/08/LRU%E7%AE%97%E6%B3%95/
